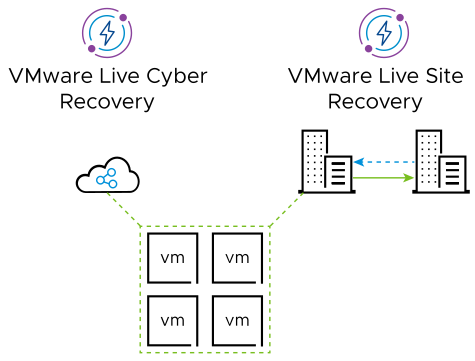
Designing a modern VMware availability and disaster recovery strategy often feels like a forced choice between two competing priorities: achieving near-zero downtime or protecting workloads across long geographic distances. VMware Stretched Clusters are exceptionally effective at delivering continuous availability across metro-area data centers, while VMware Live Site Recovery (VLSR) is designed to orchestrate recovery to sites located hundreds or even thousands of miles away. Traditionally, organizations choose one approach over the other based on risk tolerance, latency constraints, and budget.
By combining a VMware Stretched Cluster for local or metro-level resilience with VMware Live Site Recovery for regional or cross-country disaster recovery, organizations can create an architecture that delivers the best of both worlds. This layered approach provides active-active availability for common infrastructure failures while still offering robust, orchestrated recovery for large-scale or catastrophic events. Understanding how and why to combine these technologies is key to building a resilient and operationally sound infrastructure strategy.
At the core of this architecture are two complementary building blocks. A VMware Stretched Cluster extends a single vSphere cluster across two physically separate sites within a low-latency boundary. Because storage is synchronously replicated and hosts operate as part of the same logical cluster, workloads can run actively at both locations. This design enables near-zero recovery point objectives and extremely low recovery time objectives for host, rack, or even full-site failures. Applications are largely unaware of failures, making stretched clusters ideal for maintaining availability during localized outages such as power loss, hardware failures, or building-level incidents.
However, these benefits come with inherent limitations. Stretched clusters are highly sensitive to latency and are generally constrained to round-trip times of five milliseconds or less. They also depend on synchronous storage replication, which makes them unsuitable for protecting workloads across long distances. As a result, while stretched clusters excel at handling local and metro failures, they are not designed to address regional disasters or widespread network outages.
This is where VMware Live Site Recovery plays a critical role. VLSR provides policy-based replication, automated orchestration, and controlled failover between independent sites that may be separated by significant geographic distances. Rather than focusing on continuous availability, VLSR emphasizes recoverability. It enables organizations to define recovery plans, test them non-disruptively, and execute failovers in a predictable and repeatable manner. Recovery point objectives are typically measured in minutes, and recovery time objectives range from minutes to hours, depending on the environment and the complexity of the applications being recovered. This makes VLSR particularly well-suited for protecting against regional outages, natural disasters, and major infrastructure failures.
When viewed individually, each solution addresses a different failure domain. Host-level failures are handled by vSphere High Availability, while rack or metro-site outages are best mitigated by a stretched cluster. Regional disasters and planned migrations, on the other hand, are squarely within the domain of Live Site Recovery. By layering VLSR on top of a stretched cluster, organizations gain continuous availability for everyday operational issues while also ensuring automated disaster recovery for rare but high-impact events. This separation of responsibilities creates clear operational boundaries between high availability and disaster recovery, improving overall business continuity without introducing unnecessary complexity.
A common way to implement this strategy is through a three-site reference architecture. In this design, two metro-proximate sites—often referred to as Site A and Site B—form a VMware Stretched Cluster. Workloads run in an active-active fashion across both locations, with synchronous storage replication ensuring data consistency. A third site, Site C, is located at a much greater distance and operates as an independent vSphere cluster. Data from the stretched cluster is asynchronously replicated to this remote site, and VMware Live Site Recovery orchestrates failover when a disaster scenario occurs. Under normal conditions, workloads remain within the stretched cluster, and the remote site serves purely as a recovery target.
Several key design considerations are essential for this architecture to function correctly. First, the stretched cluster must be treated as a single protected entity from a replication perspective. Replication to the remote site must remain consistent regardless of which metro site is actively servicing workloads. This requires careful coordination between storage platforms or the use of replication technologies that explicitly support stretched-cluster topologies.
Equally important is maintaining clarity around failure domains. The stretched cluster should be responsible for availability, while Live Site Recovery should be reserved for disaster recovery. If one metro site fails, workloads should continue running on the surviving site without triggering a DR event. Live Site Recovery should only be invoked when both metro sites are unavailable or during planned recovery exercises or migrations. Blurring this distinction often leads to unnecessary failovers and operational confusion.
Networking strategy also differs significantly between the stretched cluster and the remote DR site. Within the stretched cluster, Layer 2 extension or consistent network identity is typically required to enable fast, transparent failover with minimal IP changes. At the remote site, however, Layer 3 changes should be expected. Live Site Recovery recovery plans can handle IP customization, DNS updates, and load balancer reconfiguration, allowing the DR site to remain operationally independent while still supporting automated recovery.
Recovery planning and testing are critical to the success of this approach. Tiered recovery plans should prioritize mission-critical workloads, followed by supporting services and then non-critical systems. Regular, non-disruptive testing using Live Site Recovery ensures that boot order, application dependencies, network mappings, and operational procedures remain valid over time. Organizations that skip testing often discover gaps only during real incidents, when remediation is most difficult.
Operational simplicity should remain a guiding principle throughout the design. Clear runbooks must define when to rely on high availability versus when to initiate disaster recovery. Monitoring systems should differentiate between metro-level failures and regional events, and DR invocation should always be a deliberate, informed decision rather than an automatic response.
There are also common pitfalls to avoid. Treating Live Site Recovery as a replacement for stretched cluster failover, ignoring replication consistency in active-active environments, overcomplicating networking at the DR site, or skipping regular DR testing because a stretched cluster is in place all undermine the effectiveness of the architecture. Availability alone does not guarantee recoverability, and the two must be addressed independently.
In conclusion, VMware Stretched Clusters and VMware Live Site Recovery are not competing technologies but complementary layers within a mature resilience strategy. By combining metro-level continuous availability with long-distance, orchestrated disaster recovery, organizations can protect against both routine failures and worst-case scenarios without sacrificing performance or operational clarity. This “best of both worlds” approach delivers resilience that scales with business risk rather than infrastructure constraints, providing a foundation for dependable and future-ready VMware environments.