What is a stretched cluster
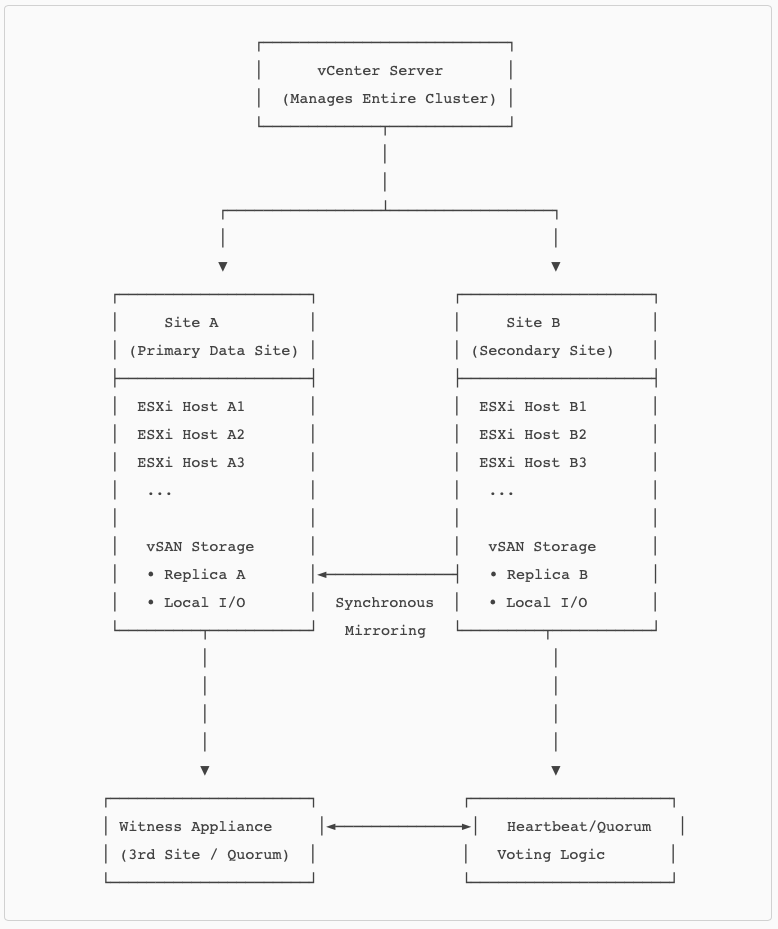
A vSAN stretched cluster is a deployment model where a single vSAN cluster is extended across two geographically separated data centers, with a third site hosting the Witness Appliance. This architecture provides site‑level resilience by synchronously mirroring data between two active sites, ensuring that each site holds a full copy of the data. The design enables the cluster to tolerate the complete loss of an entire site while maintaining continuous VM availability.
From an architectural standpoint, a stretched cluster behaves like a single logical cluster but is divided into two fault domains known as Site A and Site B. All writes are committed synchronously to both sites, ensuring strict consistency.
The Witness site provides quorum and ensures deterministic failover during partition scenarios. This enables the cluster to distinguish between a site failure and a network partition, providing predictable, policy‑driven behavior.
A major architectural advantage of stretched clusters is that they deliver Active/Active availability across two sites. Workloads can run in either site and continue operating seamlessly if the opposite site becomes unavailable. VMware’s topology description for vSAN 8 stretched clusters emphasizes the configuration of Site A, Site B, and the Witness, along with the requirements for consistent networking and communication between hosts across sites. This operational model provides disaster‑avoidance capabilities with near‑zero RPO, since writes are acknowledged only after being committed to both active sites.
Failure protection
The stretched cluster provides PFTT=1, data mirroring (RAID1 setup). Each of the two fault domains contains a full copy of the data.
Which protects the infrastructure for these failure scenarios, compared to a non-stretched vSAN.
| Failure Scenario | Standard vSAN | Stretched vSAN |
|---|---|---|
| Host failure | ✔ Protected | ✔ Protected |
| Disk/SSD/DG failure | ✔ Protected | ✔ Protected |
| Network isolation (single host) | ✔ Protected | ✔ Protected |
| Rack/power-zone failure (if FD used) | ✔ Possibly | ✔ Always (one site can fail) |
| Full site/datacenter outage | ❌ Not protected | ✔ Protected (site-level mirroring) |
| Metro fiber cut / site isolation | ❌ Not possible | ✔ Witness decides the surviving site |
| Multi-host cascading failure | ❌ Not protected | ✔ Survives as long as one site is intact |
| Disaster avoidance (zero RPO) | ❌ Requires SRM | ✔ Native to stretched vSAN |
SFTT (Second Failure to tolerate)
A vSAN Stretched cluster can be configured for handling errors within the Site.
SFTT=0
What it means
- No local redundancy inside each site.
- Only site‑level mirroring protects the data.
- Each site holds one copy only.
Failure behavior
- A full site failure is tolerated (via PFTT=1).
- A host, disk‑group, or device failure inside a site makes the object degraded, relying on the opposite site.
- If vSAN cannot rebuild locally due to lack of free space → object enters “reduced availability – cannot repair” state.
Advantages
- Highest capacity efficiency for stretched clusters
- Lowest overhead; cuts footprint nearly in half compared to SFTT=1
- Ideal for capacity‑constrained environments
Risks
- A single host failure inside a site immediately puts the object in a degraded state
- You rely on the remote site until the rebuild completes
- Combined failures (local + remote) risk outages
SFTT=1
What it means
- Adds one local failure to tolerate inside each site.
- VMware documentation shows that adding RAID‑1/5/6 local resilience provides accessibility even if a host fails in that site before site failover is required.
In practice:
- Each site stores two local copies (RAID‑1) or local RAID‑5 (if host count allows per site).
- Total: 4 copies if using RAID‑1 across sites and RAID‑1 inside sites.
Failure behavior
- Survives one host/DG failure inside the surviving site after a site failure.
- Survives any single host failure without cross‑site I/O.
- Stretched + SFTT=1 is the VMware‑documented configuration where “Site Mirroring + RAID‑1/5/6” allows VMs to stay online during host failures inside a site without restart.
Advantages
- Strong intra‑site protection
- Site stays locally resilient even under load
- No cross‑site reads/writes during single host/DG failures
- Recommended for Tier‑1 critical workloads
Risks
- Massive capacity consumption (if using RAID‑1)
- More components → longer rebuild/resync times
- Higher operational overhead
SFTT=2
What it means
- Protects against two simultaneous host or disk‑group failures inside a site.
- Requires:
- RAID‑6 per site
- Minimum 6 hosts per site (documented requirement for RAID‑6)
Failure behavior
- Can survive a full site failure (PFTT=1) AND two host failures in the surviving site.
- VMware documentation confirms SFTT=2 with RAID‑6 inside each AZ is supported when each AZ has at least 6 hosts.
Advantages
- Extremely high availability for in‑site protection
- Appropriate for large, mission‑critical metro clusters
- Best for clusters hosting high‑density workloads (databases, ERP)
Risks
- Very high capacity cost (RAID‑6 overhead)
- Increased striping/parity complexity
- Requires large host counts per site
- More sensitive to performance bottlenecks if cluster is near capacity
SFTT=3
What it means
- Protects against three host/DG failures inside a site.
- Supported only if the site has enough hosts to satisfy:
- RAID‑1 for SFTT=3 → minimum 4 hosts per site
- RAID‑5 or RAID‑6 only if host counts per site meet min requirements
Failure behavior
- Can survive:
- One full site outage (PFTT=1)
- Three local failures inside the surviving site
Advantages
- Maximum intra‑site protection possible
- Provides data safety even during cascading failures
- Suitable for highly regulated, mission‑critical workloads
Risks
- Massive capacity overhead
- Large component counts → large resync operations
- Higher operational complexity
- Only feasible in large per‑site host populations (≥8–10 hosts)
Summary Table
| SFTT Value | Local Protection | Failure Coverage | Requirements | Impact |
|---|---|---|---|---|
| 0 | None | 1 site failure only | 1 host/site minimum | Best capacity efficiency; lowest protection |
| 1 | 1 local failure | Site failure + 1 host failure | ≥3–4 hosts/site | Doubling of copies; best balance of protection/capacity |
| 2 | 2 local failures | Site failure + 2 host failures | ≥6 hosts/site (RAID‑6) | Very strong protection; heavy overhead |
| 3 | 3 local failures | Site failure + 3 host failures | Large host count/site | Maximum resiliency; highest overhead |
Erasure Coding vs Mirroring
RAID‑5/6 is not supported for PFTT (site mirroring)
The site‑level protection rule (“Site Disaster Tolerance”) in stretched clusters always uses mirror copies across sites — never parity.
VMware states that in stretched clusters, the RAID‑5/6 setting applies only to the site disaster tolerance setting, and cannot be used to stretch erasure coding across sites.
https://www.vmware.com/docs/vsan-stretched-cluster-guide
Meaning:
- PFTT=1 (dual‑site mirroring) = must be RAID‑1 across sites
- RAID‑5/6 cannot be used for the stretched copy
RAID‑5 and RAID‑6 are supported for SFTT (local per‑site protection) from vSAN8
- SFTT=1 using RAID‑5 (requires ≥4 hosts per site)
- SFTT=2 using RAID‑6 (requires ≥6 hosts per site)
- SFTT=3 using RAID‑1 (needs enough hosts)
Final thoughts
A vSAN stretched cluster provides the highest level of site‑level resilience available in vSAN by synchronously mirroring data across two active sites and relying on a Witness for deterministic quorum. VMware documentation describes that in stretched mode, PFTT governs site-level failures, while SFTT governs in‑site host or disk‑group failures. The combination of these policy layers determines a VM’s resilience during single‑site outages, host failures, partitioning, or multi‑component failures inside the remaining operational site. This architectural design enables zero‑RPO failure handling for metropolitan deployments, but it also forces administrators to make clear decisions about the trade‑off between capacity efficiency, failure tolerance, and operational complexity.
From an architectural standpoint, stretched clusters must always use PFTT=1 for dual‑site mirroring. Parity protection (RAID‑5/6) cannot be used across sites, as only RAID‑1 mirroring satisfies the synchronous, low‑latency, site‑level replication model in the vSAN stretched topology.
SFTT of 1 is a standard because it protects the site against internal issues without degrading. Increasing SFTT to 2 or 3 creates additional redundancy within each site. VMware’s failure‑scenario documentation makes clear that after losing an entire site (PFTT=1), the surviving site must tolerate additional local failures to keep VMs running without data becoming inaccessible. Higher SFTT values are therefore beneficial in environments where: [techdocs.b…oadcom.com]
- Large clusters (≥6–8 hosts per site) support RAID‑6 parity or multiple mirrored copies.
- Mission‑critical workloads cannot tolerate downtime even after cascading failures.
- Hardware fault domains inside a site (racks, power zones, chassis) create additional correlated failure risks.
- Maintenance operations may temporarily reduce local redundancy (e.g., rolling patching or host evacuations).
Cloud‑validated configurations reinforce this guidance: stretched clusters can support SFTT=2 with RAID‑6 and SFTT=3 with RAID‑1 for environments that meet host‑count requirements, specifically to handle more than one local failure per site while still providing full site‑level protection through PFTT=1. [ntpro.nl]
However, while SFTT>1 provides exceptional resilience, it also comes with significant operational and capacity overhead. Additional local copies or parity groups increase object component count and resync workload, amplify capacity consumption, and raise the rebuild space required to remain compliant—especially in stretched clusters where free capacity must be carefully managed to avoid “reduced availability – cannot repair” states during failures. Architecturally, SFTT>1 is therefore reserved for environments with ample per‑site resources, high‑availability requirements, and strict uptime SLAs.
In summary, choosing SFTT beyond 1 in a stretched vSAN cluster is an architectural decision that should be made when the business requires continued VM survivability after a complete site outage plus multiple host or disk‑group failures inside the remaining site, and where the cluster has enough hosts and capacity to support RAID‑6 or multiple RAID‑1 mirrors. For most production environments, SFTT=0 or 1 offers the right balance between resilience and resource efficiency, but SFTT=2 or 3 becomes the right choice for large, mission‑critical, fault‑sensitive deployments that must continue operating even in the face of rare but catastrophic compound failure scenarios.